
Кодування символів.
Набір символів, кодування символів, таблиця символів (англ. character set, character encoding) — певна таблиця кодування скінченної множини символів. Така таблиця зіставляє кожному символу послідовність довжиною в один або більше байт.
Нерідко замість терміна набір символів неправильно вживають термін кодова сторінка, що означає насправді окремий випадок набору символів з однобайтовим кодуванням. Термін кодування (в комп’ютерному контексті) є синонімом терміна «набір символів».
Зараз в основному використовуються кодування двох типів: сумісні з ASCII і сумісні з EBCDIC. Переважна більшість кодувань, в тому числі UTF-8 Юнікода, — сумісні з ASCII. Кодування на базі EBCDIC (наприклад, ЄС ЕОМ ДКОІ-8) використовуються тільки на деяких мейнфреймах.
Спочатку в кожній операційній системі використовувався один набір символів. Тепер використовувані набори символів стандартизовані та залежать від типу операційної системи лише за традицією й установлюються відповідно до локалі.
Таблиця ASCII
 Юнікод, (англ. Unicode), УНІфіковане КОДування — промисловий стандарт, розроблений, щоб забезпечити цифрове представлення символів усіх писемностей світу та спеціальних символів. Удосконалений сумісно з стандартом Універсальний Набір Символів (Universal Character Set — UCS) і опублікований у формі книги Стандарт Юнікод, Юнікод складається з асортименту символів, методології кодування та комплекту (набору) стандартів кодування символів, комплекту кодових таблиць для посилань на зображення символів, списку властивостей символів таких, наприклад, як верхній і нижній регістр (розкладка), комплект довідкових даних комп’ютерних файлів, правил нормалізації, декомпозиції, зіставлення і зображення (рендерингу).
Юнікод, (англ. Unicode), УНІфіковане КОДування — промисловий стандарт, розроблений, щоб забезпечити цифрове представлення символів усіх писемностей світу та спеціальних символів. Удосконалений сумісно з стандартом Універсальний Набір Символів (Universal Character Set — UCS) і опублікований у формі книги Стандарт Юнікод, Юнікод складається з асортименту символів, методології кодування та комплекту (набору) стандартів кодування символів, комплекту кодових таблиць для посилань на зображення символів, списку властивостей символів таких, наприклад, як верхній і нижній регістр (розкладка), комплект довідкових даних комп’ютерних файлів, правил нормалізації, декомпозиції, зіставлення і зображення (рендерингу).
Стандарт запропонувала в 1991 році організація Консорціум Юнікоду (англ. Unicode Consortium), яка об’єднує найбільші ІТ-компанії (корпорації). Консорціум Юнікоду — неприбуткова (некомерційна) організація, яка координує розвиток Юнікоду, має амбітну мету замінити в кінцевому підсумку існуючі системи кодування символів Юнікодом і його системою стандартів Формат Перетворень Юнікоду (UTF, Unicode Transformation Format), тому що багато існуючих систем кодування є обмеженими в розмірі й можливостях і несумісними з багатомовними середовищами. Успіхи Юнікоду в уніфікації наборів символів призвели до його розповсюдження і домінуючого використання в інтернаціоналізації і локалізації програмного забезпечення комп’ютерів. Стандарт був використаний у багатьох новітніх технологіях, наприклад, у XML, мові програмування JavaScript і сучасних операційних системах.
Юнікод знімає старе обмеження на кодування символів лише одним байтом. Натомість використовується 17 просторів, кожен з яких визначає 65,536 кодів і дає можливість описати максимум 1 114 112 (17 * 216) різних символів. Basic Multilingual Plane (BMP) — Основна Багатомовна Площина містить майже всі символи, які ви будете коли-небудь використовувати.
Юнікод має декілька реалізацій, але найпоширенішими є дві: UTF (Unicode Transformation Format) — Формат Перетворення Юнікоду та UCS (Universal Character Set) — Універсальна Таблиця Символів. Число після UTF визначає кількість бітів, що виділені під один юніт, а число після UCS визначає кількість байтів. Універсальний набір символів задає однозначну відповідність символів кодам — елементам кодового простору, тобто невід’ємним цілим числам. UTF-8 став найпоширенішим для інтернаціональних кодувань.
UTF-8 є системою кодування зі змінною довжиною кодування символів. Це означає, що для кодування символів він використовує від 1 до 4 байт на символ. Так, перший байт UTF-8 можна використовувати для кодування ASCII, що дає повну сумісність з кодами ASCII. Перекодування кодів ASCII у кодах UTF-8 для латинських символів не збільшить розмір даних, бо для цього використовується тільки один байт на символ. Для символів інших мов, де, наприклад, для кодування треба використовувати два байти на символ, це кодування збільшує розмір даних на, приблизно, 50 % або більше.
UTF-8 дозволяє працювати в стандартизованому міжнародно прийнятому багатомовному середовищі, з порівняно незначним збільшенням обсягу даних. UTF-8 являє собою ідеальний спосіб передачі символів через Інтернет, електронну пошту, чат тощо.
Коди в стандарті Unicode поділені на декілька областей. Область з кодами від U+0000 до U+007F (про запис виду «U+xxxx» дивись нижче в розділі «Кодовий простір») містить символи набору ASCII. Далі розміщені області знаків різних писемностей, знаки пунктуації і технічні символи. Частина кодів зарезервована для використання в майбутньому. Для символів кирилиці виділені коди від U+0400 до U+052F (див. Кирилиця в Юнікоді).
Розділи стандарту Юнікод
Стандарт Unicode складається з двох основних розділів: універсальний набір символів і сімейство кодувань. Універсальний набір символів задає однозначну відповідність символів кодам — елементам кодового простору, що є невід’ємними цілими числами. Сімейство кодувань визначає машинне подання послідовності кодів універсального набору символів.
Стандарти наборів символів:
UCS-4 (англ. Universal Character Set) — 1 символ = 4 байти, всього можна закодувати 232 = 4 294 967 296 символів. Проте максимальна кількість Юнікод-символів на сьогодні — 220 + 216 = 1 114 112.
UCS-2 (англ. Universal Character Set) — 1 символ = 2 байти, всього можна закодувати 216 = 65 536 символів.
Стандарти кодувань:
UTF-32 (англ. Unicode Transformation Format — формат перетворення Юнікода) — один із способів кодування символів із Unicode у вигляді 32-бітових послідовностей. 1 символ = 32 біти.
UTF-16 — один із способів кодування символів із Unicode у вигляді 16-бітних послідовностей. Символи з кодами менше 0x10000 (216) представляються як є (одна 16-бітова послідовність), а символи з кодами 0x10000–0x10FFFE — у вигляді двох 16-бітових послідовностей (так звана «сурогатна» пара), перша з яких лежить в діапазоні 0xD800–0xDBFF, а друга — 0xDC00–0xDFFF. Легко бачити, що існує 210 * 210 = 220 таких комбінацій. А загальна кількість можливих символів 220 + 216 = 1 114 112. Слід зазначити, що за стандартом ніякі символи не можуть мати кодів власне з діапазону 0xD800-0xDFFF, так що розшифровка кодування завжди однозначна. Втім, в переважній більшості випадків текст в UTF-16 є просто послідовністю символів з UCS-2, оскільки символи Unicode після коду 0x10000 використовуються вкрай рідко.
UTF-16LE та UTF-16BE — у потоці даних UTF-16 старший байт може записуватися або перед молодшим (UTF-16 Big Endian або UTF-16BE), або після молодшого (UTF-16 Little Endian або UTF-16LE). Іноді кодування Юнікода Big Endian (UTF-16BE) називають Юнікодом із зворотним порядком байтів. Аналогічно існує два варіанти 32-бітового кодування: UTF-32LE та UTF-32BE.
UTF-8 — поширене сьогодні кодування, що реалізовує представлення Юнікода, сумісне з 8-бітовим кодуванням тексту. Текст, що складається тільки з символів з номером менше 128, при записі в UTF-8 перетворюється на звичайний текст ASCII. І навпаки, в тексті UTF-8 будь-який байт із значенням менше 128 зображає символ ASCII з тим же кодом. Решта символів Юнікода зображається послідовностями завдовжки від 2 до 6 байтів (реально тільки до 4 байт, оскільки використання кодів більше 2²¹ не планується), в яких перший байт завжди має вид 11xxxxxx, а інші — 10xxxxxx.
Простіше кажучи, у форматі UTF-8 символи латинського алфавіту, розділові знаки і керуючі символи ASCII, записуються ASCII-кодами, а решта всіх символів кодується за допомогою октетів (послідовності завдовжки 8 бітів) зі старшим бітом 1. У результаті, навіть якщо програма не розпізнає Юнікод, то латинські букви, арабські цифри і розділові знаки зображатимуться правильно.
Символи UTF-8 отримують з Unicode таким чином:
Unicode UTF-8 0x00000000 — 0x0000007F: 0xxxxxxx
0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Також теоретично можливі, але не включені в стандарти:
Unicode UTF-8 0x00200000 — 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 — 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Висновки
Для опрацювання текстових повідомлень з використанням комп’ютера символи повідомлення кодують числами. Для кодування тексту використовують таблиці кодів символів, у яких для кожного символа, що може бути використаний у текстовому повідомленні, ставиться у відповідність деяке число. У 1963 р. у США було розроблено набір таких кодів символів для передавання повідомлень телетайпом. Пізніше він став стандартом для використання в комп’ютерній техніці й отримав назву таблиці кодів символів ASCII. Таблиця кодів символів А8СІІ містить коди літер лише англійського алфавіту. Для кодування літер інших алфавітів було розроблено інакші таблиці кодів символів. Наприклад, таблиці КОІ8-Н (КОІ – код обміну інформацією) і Windows-1251 містять без змін усі коди таблиці А8СІІ, а також – коди літер кирилиці. Цим літерам ставляться у відповідність натуральні числа від 128 до 255. Таблиця кодів символів Windows-1251 є стандартом для кодування літер кирилиці в операційній системі Windows. У ній, наприклад, літері «а» українського алфавіту ставиться у відповідність число 224, літері «і» -число 179, літері «ґ»- число 180 та ін.Наразі у новітніх операційних системах використовується таблиця кодів Юнікод.
Характерна особливість набору символів (UCS) — символи завжди фіксованої довжини:
- UCS-2 — 1 символ = 2 байти (лише одна площина з 17-ти)
- UCS-4 — 1 символ = 4 байти (65 тис. площин не використані)
Характерна особливість кодування (UTF) — символи НЕ завжди фіксованої довжини:
- UTF-32 — єдине кодування з фіксованою довжиною символів, 1 символ = 32 біти = 4 байти, тому можна сказати, що код символу в UCS-4 дорівнює коду символу в UTF-32.
- UTF-16 — коди символів < 216 однозначно відповідають кодам символів з набору UCS-2. Коди решти символів (символи з кодом >= 216) є однозначними тільки для UTF-16.
- UTF-8 — коди символів < 128 однозначно відповідають кодам символів верхньої частини ASCII таблиці. Коди решти символів (символи з кодом >= 128) є однозначними тільки для UTF-8.
Твердження «1 байт = 1 символ» є застарілим і в переважній більшості практичних випадків є хибним. Довжина символу НЕ є фіксованою (виняток складає кодування UTF-32 та ASCII таблиця). Юнікод у програмах — добра платформа для підтримки багатомовності.
Колірна модель — це спосіб кодування кольорів у вигляді упорядкованого набору числових значень певних базових компонентів.
 Модель RGB — це апаратно-орієнтована модель, в якій кольори описуються за допомогою складання трьох базових кольорів – червоного, зеленого, синього – в різних пропорціях.
Модель RGB — це апаратно-орієнтована модель, в якій кольори описуються за допомогою складання трьох базових кольорів – червоного, зеленого, синього – в різних пропорціях.
Тому модель RGB називають адитивною (від англ. «add» складати, додавати). Модель названа за першими буквами англійських слів: R (RED) – червоний; G (GREEN) – зелений; B (BLUE) – синій.
Кожен з базових кольорів може приймати інтенсивність (насиченість) у діапазоні від 0 до 255. Повна кількість кольорів, які представляються цією моделлю, дорівнює 256*256*256 = 16 777 216. За допомогою моделі RGB описуються кольори, що отримуються змішуванням світлових променів. Дану модель використовують монітори, телевізори, сканери, слайд-проектори, кольорові лампи реклами і інші пристрої, в яких колір виходить шляхом змішування світлових пучків. Вона також використовується для опису кольорів на сторінках Інтернету в спеціальному шістнадцятковому вигляді (#RRGGBB).
Змінюючи інтенсивність свічення кольорових крапок, можна створити велике різноманіття відтінків. Якщо інтенсивність кожного з них максимальна (255), то виходить білий колір. Відсутність всіх трьох кольорів дає чорний колір. Якщо змішуються всі кольори з однаковою інтенсивністю (але не максимальною і не мінімальною), отримуємо сірий колір.
Початок відліку (0,0,0) відповідає чорному кольору. Максимальне значення RGB (1,1,1) відповідає білому кольору. (1,0,0) — червоному, (0,1, 0) — зеленому, (0,0,1) синьому. Недолік моделі RGB полягає в тому, що не всі кольори, утворені в ній, можна вивести на друк.
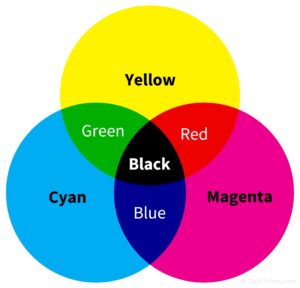 Модель CMY — це модель, що використовується для підготовки друкованих зображень, тобто для пристроїв, які реалізують принцип поглинання (віднімання) кольорів.
Модель CMY — це модель, що використовується для підготовки друкованих зображень, тобто для пристроїв, які реалізують принцип поглинання (віднімання) кольорів.Друковані зображення відрізняються від екранних зображень тим, що їх бачать не у світлі, що проходить, а у відбитому світлі, оскільки аркуш паперу не випромінює світло.
Базовими кольорами моделі CMY є кольори, які виходять у результаті віднімання основних кольорів RGB від білого. Звідси назва моделі субтрактивна (від англ. «to subtract» – віднімати). Базові кольори моделі CMY:
- C (CYAN) – блакитний = білий — червоний = зелений + синій;
- M (MAGENTA) – пурпурний = білий — зелений = червоний + синій;
- Y (YELLOW) – жовтий = білий — синій = червоний + зелений.
Системи кольорів RGB і СМУК базуються на обмеженнях, які накладаються апаратним забезпеченням (моніторами комп’ютерів у разі використання RGB і друкарських фарб у разі СМУК). Більш інтуїтивним способом опису кольору є представлення його у системі НSВ.
Модель HSB — це система кодування цілими числами таких характеристик кольору: відтінок кольору (Hue); насиченість кольору (Saturation); яскравість кольору (Brightness).
Працюємо з підручником: ст. 14 вп. 1-4, 6
Домашнє завдання ст. 14 вп. 5.
-
Кодування даних
-
Апаратне забезпечення комп'ютера
- Урок 4. Архітектура комп’ютера. Процесор, його призначення. Пам’ять комп’ютера. Зовнішні та внутрішні запам’ятовуючі пристрої.
- Урок 5. Пристрої введення та виведення даних. Пристрої, що входять до складу мультимедійного обладнання. Технічні характеристики складових комп’ютера.
- Урок 6. Історія засобів опрацювання інформаційних об’єктів.
- Урок 7. Види сучасних комп’ютерів та їх застосування. Практична робота №2. Конфігурація комп’ютера під потребу.
-
Опрацювання текстових даних
- Урок 7. Повторення раніше вивченого матеріалу з теми “Текстовий процесор”
- Урок 8. Пошук та заміна фрагментів тексту. Створення, редагування та форматування символів, колонок, списків в текстовому документі. Недруковані знаки.
- Урок 9. Створення, редагування та форматування таблиць.
- Урок 10. Створення, редагування та форматування графічних об’єктів в текстовому документі.
- Урок 12. Практична робота №3. Створення текстового документа, що містить об’єкти різних типів.
- Урок 13. Створення і опрацювання складних за структурою документів
- Урок 14. Автоматизоване створення змісту.
- Урок 15. Практична робота №4. Форматування документу. Створення титульної сторінки. Автоматизоване створення змісту.
- Урок 16. Створення та опрацювання складних за структурою документів.
-
Алгоритми та програми. Основи подвійно- та об'єктно-орієнтованого програмування
- Урок 13. Поняття мови програмування. Складові мови програмування.
- Урок 14. Знайомство з середовищем програмування.
- Урок 15. Поняття події, обробника події.
- Урок 16. Практична робота №5. Створення об’єктно-орієнтованої програми, що відображає вікно повідомлення.
- Урок 17. Елемент керування “кнопка”.
- Урок 18. Елемент керування “напис”.
- Урок 19. Складання програм, що обробляють натискання кнопок та визначають вміст написів на формі.
- Урок 20. Практична робота №6. Створення програми з кнопками та написами.
-
Алгоритми роботи з об'єктами та величинами
- Урок 21. Поле його властивості (Python)
- Урок 22. Величини (змінні і константи), їхні властивості. (Python)
- Урок 23. (Python) Практична робота №7. Складання та виконання лінійних алгоритмів опрацювання величин в навчальному середовищі програмування.
- Урок 24. Налагодження програм. (Python)
- Урок 25. Використання налагоджувача програм у візуальному середовищі програмування. Покрокове виконання програм, перегляд значень змінних під час виконання програми. (Python)
- Урок 26. Величини логічного типу, операції над ними.
- Урок 27. Алгоритми з розгалуженнями для опрацювання величин. (Python)
- Урок 28. Алгоритми з розгалуженнями для опрацювання величин. (Python)
- Урок 29 (Python). Складені умови. Пошук найбільшого та найменшого серед кількох значень.
- Урок 30. (Python) Інструктаж з БЖД. Практична робота 9. Складання та виконання алгоритмів з розгалуженнями для опрацювання величин.
- Урок 31. (Python) Елементи для введення даних: прапорець.
- Урок 32. (Python) Елементи для введення даних: перемикач.
- Урок 33. (Python) Алгоритми з повтореннями для опрацювання величин. Цикл з лічильником.
- Урок 34. (Python) Цикл з передумовою. Складання алгоритмів опрацювання величин у навчальному середовищі програмування, їх налагодження і виконання.
- Урок 35. (Python) Співвідношення типів даних та елементів для введення даних, зчитування даних з елементів введення.
- Урок 36. (Python) Розв’язання задач
- Урок 37. (Python) Практична робота №9. Складання та виконання алгоритмів з повтореннями та розгалуженнями для опрацювання величин.
- Урок 38 (Python). Повторення вивченого матеріалу.
- Урок 21. Поле, його властивості.
- Урок 22. Величини (змінні і константи), їхні властивості.
- Урок 23. Практична робота №7. Складання та виконання лінійних алгоритмів опрацювання величин в навчальному середовищі програмування.
- Урок 24. Налагодження програм.
- Урок 25. Використання налагоджувача програм у візуальному середовищі програмування. Покрокове виконання програм, перегляд значень змінних під час виконання програми.
- Урок 28. Алгоритми з розгалуженнями для опрацювання величин.
- Урок 30. Складені умови. Пошук найбільшого та найменшого серед кількох значень.
- Урок 30. Елементи для введення даних: перемикачі, прапорці.
- Урок 31. Елементи для введення даних: випадаючі списки.
- Урок 32. Алгоритми з повтореннями для опрацювання величин. Цикл з лічильником.
- Урок 33. Цикл з передумовою. Складання алгоритмів опрацювання величин у навчальному середовищі програмування, їх налагодження і виконання.
- Урок 36. Практична робота №9. Складання та виконання алгоритмів з повтореннями та розголуженнями для опрацювання величин.
- Урок 37. Відображення базових графічних примітивів. Відображення рисунків із зовнішніх файлів.
- Урок 38. Практична робота №10. Складання та виконання алгоритмів з графічним відобреженням даних.
-
Опрацювання мультимедійних об’єктів
- Урок 39. Поняття мультимедіа. Формати аудіо- та відеофайлів.
- Урок 40. Додавання відеокліпів, звукових ефектів і мовного супроводу до слайдової презентації.
- Урок 41. Елементи анімації. Інструктаж з БЖД. Практична робота 11. Розробка презентацій з елементами анімації, відеокліпами, звуковими ефектами та мовним супроводом.
- Урок 42. Програмне забезпечення для опрацювання об’єктів мультимедіа. Захоплення аудіо та відео, створення аудіо-, відео фрагментів. Засоби перетворення аудіо- та відеоформатів.
- Урок 43. Програми для редагування аудіо- та відеоданих. Загальні поняття про відеофільм.
- Урок 44. Побудова аудіо- та відеоряду. Додавання до відеокліпу відеоефектів та налаштування переходів між його фрагментами.
- Урок 45. Налаштування часових параметрів аудіо- та відеоряду. Інструктаж з БЖД. Практична робота 12. Створення відеокліпу. Додавання відеоефектів, налаштування часових параметрів аудіо- та відеоряду.
- Урок 46.Сервіси розміщення аудіо та відео файлів в Інтернеті.
- Урок 47. Інструктаж з БЖД. Практична робота 13. Розміщення аудіо- та відеоматеріалів в Інтернеті.
- Урок 48. Підсумковий урок з теми: «Опрацювання мультимедійних об’єктів»
-
Створення та публікація веб-ресурсів
Створення та публікація веб-ресурсів
- Урок 49. Структура веб-сайтів, різновиди веб-сайтів. Різновиди веб-сторінок. Етапи створення веб-сайтів. Основи веб-дизайну
- Уроу 50. Основи веб-дизайну
- Урок 51. Поняття про засоби автоматизованої розробки веб-сайтів, редактор веб-сайтів з графічним інтерфейсом
- Урок 52. Поняття про систему керування вмістом сайту. Поняття хостингу. Автоматизоване створення статичної веб-сторінки, вибір її типу й оформлення.
- Урок 53. Наповнення веб-сторінки текстом та графічним матеріалом, створення гіперпосилань, завантаження файлів
- Урок 54. Інструктаж з БЖД. Практична робота №14. Автоматизоване створення веб-сайту
- Уроки 55-56. Поняття про мову розмітки HTML. Структура веб-сторінки. Оформлення тексту. Текстові елементи веб-сторінки, теги та їх атрибути.
- Урок 57. Інструктаж з БЖД. Практична робота 15. “Створення веб-сторінки за допомогою «Мови гіпертекстової розмітки»
- Урок 58. Малюнки. Гіперпосилання
- Урок 59-60. Таблиці на веб-сторінках. Списки на веб-сторінках
- Урок 61. Інструктаж з техніки безпеки. Практична робота 16 «Створення веб-сторінки за зразком з використанням таблиць, списків та малюнків»
0.00 на основі 0 рейтингів